Manage web scraping. From one platform.
AI-native web scraping orchestration. Our AI turns any page into schema-aligned JSON and falls back across providers and models when one fails.
Replace 11+ tools with one
AI-native
AI that turns any page into structured data
Our proprietary AI extraction engine reads raw HTML, matches it to your schema, and returns validated JSON. Purpose-built for scraping - multi-step prompting, schema enforcement, and confidence scoring layered on top of frontier models.
Proprietary extraction engine
Our own AI pipeline, purpose-built for web data. Multi-step prompting, schema enforcement, and confidence scoring that general LLMs don't do out of the box.
Smart model routing
Start with cheaper models, escalate to stronger ones only when confidence drops. Pay for intelligence only when you need it.
AI + provider fallback
If a model or provider fails, the chain reruns on the next one automatically - the same fallback logic your requests already use.
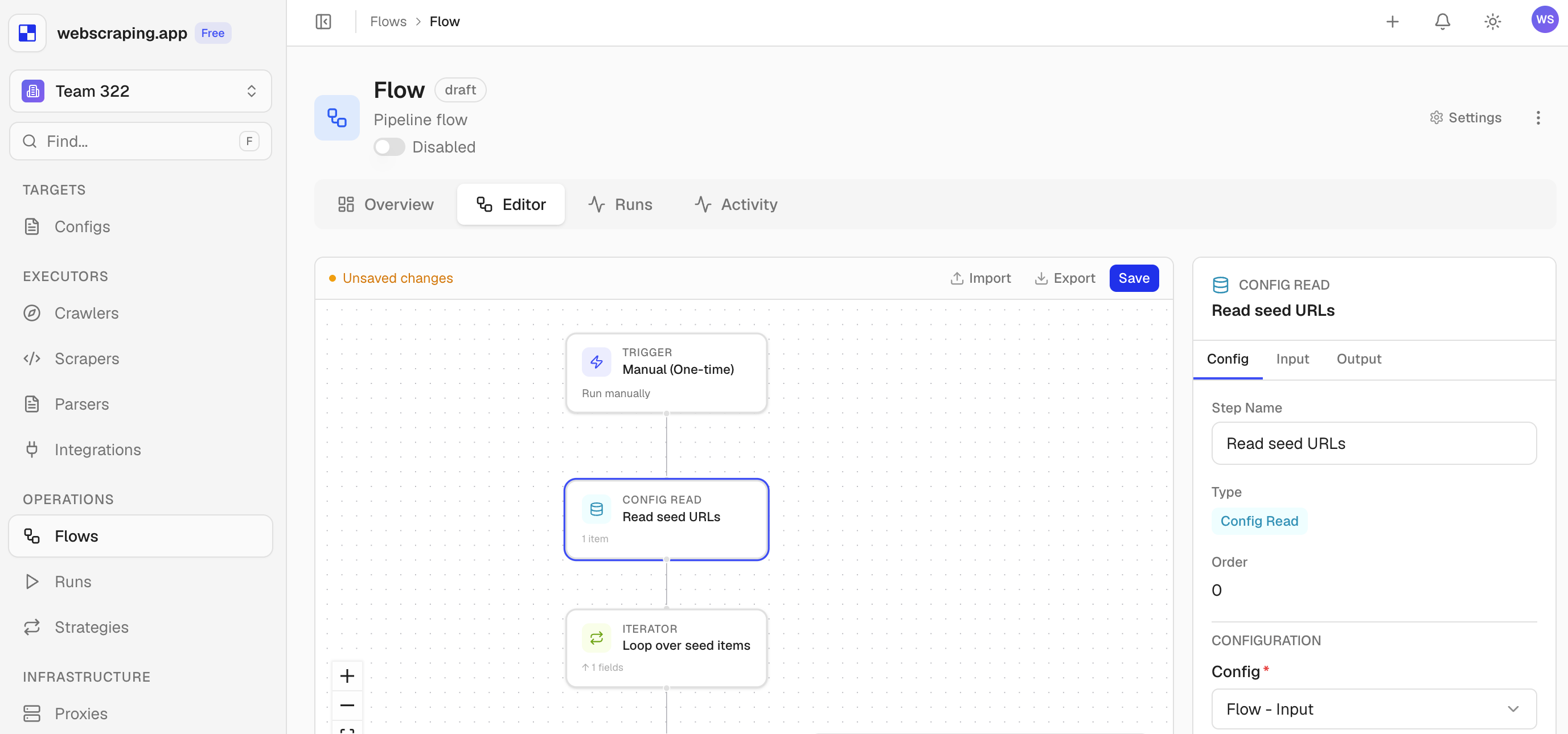
How It Works
Define a flow. Watch it run.
Three steps from raw URL to structured data.
Configure
Pick providers, set fallback order, define your output schema.
Orchestrate
The engine routes requests, handles failures, and retries across providers.
Monitor
Watch every step, fallback and result - in real time.
Features
Built for reliability, not demos
Works with the tools you already use
Your Data Layer
One dataset connects crawlers and scrapers. Here's how.
Typed schemas
Define fields once. Every item validated automatically.
Data branches
Isolate data per client or environment. Same schema, separate items and variables.
Input/output mapping
Bind scraper params to config fields. Zero custom code.
Crawler finds 142 URLs
Writes each URL as a new item into Config
Products
Scraper reads each URL
Picks items from Config as input parameters
Results stored as artifacts
Every run keeps structured output - browse, download, or pipe into the next step